Vergraben unter Big Data: Herausforderungen und Bedenken rund um die Sicherheit


Alex Bekker ist Leiter der Abteilung Data Analytics in ScienceSoft, einem Unternehmen für IT-Beratung und Softwareentwicklung. Alex hat mehrere Projekte in den Bereichen wie Business Intelligence, Big Data, Data Analytics geleitet und auch den Unternehmen geholfen, die Vorteile von Data Science und maschinellem Lernen zu nutzen. Zu seinen größten Projekten gehören: Big-Data-Analyse für die Musterendeckung in der Mediennutzung in mehr als 10 Ländern; die Analyse von Eigenmarken-Produkten für mehr als 18.500 Produzenten, BI für 200 Gesundheitszentren.
Während eine "Lawine" aus Big Data vom Berg herunterstürzt und an Geschwindigkeit und Volumen gewinnt, versuchen viele Unternehmen damit Schritt zu halten. Dabei vergessen sie völlig, Masken, Helme, Handschuhe und manchmal sogar Skier anzuziehen. Ohne diese Ausrüstung entsteht die Gefahr, unter den "Schneemassen" von Big Data vergraben zu bleiben. Und alle benötigten Vorsichtsmaßnahmen mit hoher Geschwindigkeit zu treffen, kann auch zu spät oder zu schwierig sein.
Es ist nicht immer ein kluger Schachzug, die Sicherheitsaspekte von Big Data niedrig zu priorisieren und sie bis zu einem späteren Zeitpunkt in Big-Data-Projekten vorzuschieben. Nicht ohne Grund wird der Ansatz "Sicherheit zuerst" verfolgt. Zugleich geben wir zu, dass die Sicherung von Ihrem Big Data bestimmte Sorgen und Herausforderungen mitbringt, deshalb ist es mehr als hilfreich und empfehlenswert, sich mit diesem Thema vertraut zu machen.
Und so "überraschend" ist es, dass fast alle Sicherheitsherausforderungen und -lüken von Big Data daraus resultieren, dass es groß ist. Sehr groß.
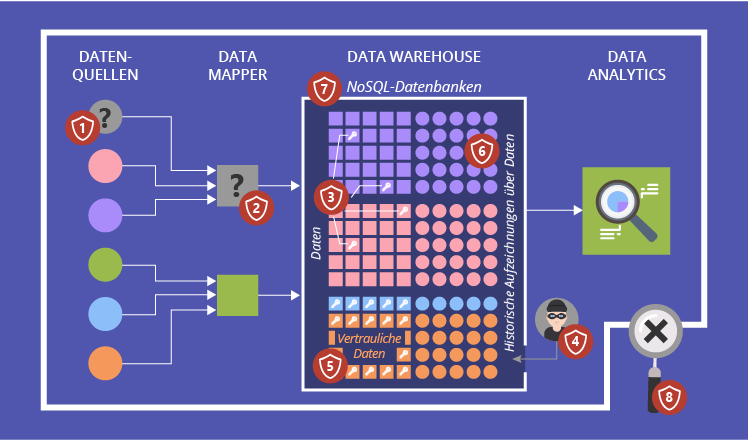
Kurzübersicht
Die Sicherheitprobleme stellen für jedes System ernsthafte und massive Bedrohungen dar. Aus diesem Grund ist es sehr wichtig, Sicherheitslücken zu kennen, um sie rechtzeitig zu schließen. Umso mehr müssen Unternehmen für die Sicherheit von ständig wachsenden Datenmengen sorgen. In diesem Blogbeitrag decken unsere Experten in Big-Data-Beratung die meisten harten Sicherheitsherausforderungen im Bezug auf Big Data ab:
- Schwachstellen bei der Generierung von falschen Daten
- Das potenzielle Vorhandensein von nicht vertrauenswürdigen Mappern
- Probleme beim kryptografischen Schutz
- Das mögliche Mining von sensiblen Informationen
- Schwierigkeiten bei der granulären Zugriffskontrolle
- Probleme mit der Datenherkunft
- Die Hochgeschwindigkeitsentwicklung von NoSQL-Datenbanken und mangelnder Sicherheitsfokus
- Fehlende Sicherheitsaudits
Jetzt betrachten wir sie jedes einzelne Big-Data-Sicherheitsproblem sowie dessen mögliche Lösungeswege etwas näher.
1. Schwachstellen bei der Generierung von falschen Daten
Bevor wir alle Sicherheitsherausforderungen von Big Data aus betrieblicher Sicht in Angriff nehmen, sollten wir Bedenken bezüglich der Generierung von falschen Daten erwähnen. Um die Qualität Ihrer Big-Data-Analyse gezielt zu beeinträchtigen, können Cyberkriminelle falsche Daten erzeugen und diese in Ihren Data Lake "eingießen". Wenn Ihr Produktionsunternehmen beispielsweise Sensordaten verwendet, um fehlerhafte Produktionsprozesse zu erkennen, können Cyberkriminelle in Ihr System eindringen und Ihre Sensoren falsche Ergebnisse, z. B. falsche Temperaturen, anzeigen lassen. Auf diese Weise können Sie alarmierende Trends übersehen und die Möglichkeit verpassen, Probleme rechtzeitig zu lösen, bevor ernsthafte Schäden durch Störungen und Ausfälle verursacht werden. Solche Herausforderungen können durch die Betrugserkennung (Fraud Detection) gemeistert werden.
2. Das potenzielle Vorhandensein von nicht vertrauenswürdigen Mappern
Sobald Ihr Big Data gesammelt wurde, wird es parallel verarbeitet. Eine der verwendeten Methoden zur Verarbeitung ist das MapReduce-Paradigma. Nachdem die Daten in mehrere Portionen zerteilt sind, verarbeitet ein Mapper diese und verteilt sie in speziellen Speicheroptionen. Wenn ein Fremder einen Zugriff auf die Code Ihrer Mapper hat, kann er die Einstellungen der vorhandenen Mapper ändern oder "fremde" hinzufügen. Auf diese Weise kann Ihre Datenverarbeitung im Grunde genommen ruiniert werden: Cyberkriminelle lassen Mapper inadäquate Listen von Schlüssel/Wert-Paaren erstellen.
Aus diesem Grund werden die Ergebnisse des Reduce-Prozesses fehlerhaft sein. Außerdem können Fremde einen Zugriff auf sensible Informationen erhalten. Das Problem besteht darin, dass es nicht allzu schwierig ist, einen solchen Zugriff zu bekommen, weil Big-Data-Technologien im Allgemeinen keine zusätzliche Sicherheitsstufe zum Datenschutz bieten. Sie neigen normalerweise dazu, sich auf Perimeter-Sicherheitssysteme zu verlassen. Aber wenn diese fehlerhaft sind, wird Ihr Big Data zu einer tief hängenden Frucht.
3. Probleme bei dem kryptografischen Schutz
Obwohl die Verschlüsselung eine bekannte Methode zum Schutz von sensiblen Informationen ist, steht sie auf unserer Liste der Probleme bei der Datensicherheit. Trotz der Möglichkeit und damit verbundenen Notwendigkeit, Big Data zu verschlüsseln, wird diese Sicherheitsmaßnahme oft ignoriert. Sensible Daten werden in der Regel ohne Verschlüsselung zum Schutz in der Cloud gespeichert. Und der Grund dafür, so unüberlegt zu handeln, ist einfach: ständige Verschlüsselung und Entschlüsselung von riesigen Datenmengen führen zu einer Verlangsamung, was den Verlust des ursprünglichen Vorteils von Big Data – Geschwindigkeit – bedeutet.
4. Das mögliche Mining von sensiblen Informationen
Perimeterbasierte Sicherheit wird normalerweise für den Schutz von Big Data verwendet. Das bedeutet, dass alle "Ein- und Ausgänge" gesichert sind. Aber was IT-Spezialisten innerhalb Ihres Systems tun, bleibt ein Rätsel.
Solch eine mangelnde Kontrolle von Ihrer Big-Data-Lösung kann dazu führen, dass Ihre korrupten IT-Spezialisten oder böse Geschäftskonkurrenten ungeschützte Daten zu ihrem eigenen Vorteil gewinnen und verkaufen. Ihr Unternehmen kann dabei enorme Verluste erleiden, wenn diese Informationen mit der Einführung neuer Produkte/Dienstleistungen, den Finanzoperationen des Unternehmens oder personenbezogenen Benutzerinformationen verbunden sind.
Hier können Daten durch Hinzufügen zusätzlicher Perimeter besser geschützt werden. Auch die Sicherheit Ihres Systems könnte von einer Anonymisierung profitieren. Wenn jemand persönliche Daten von Benutzern mit fehlenden Namen, Adressen und Telefonen erhält, können sie praktisch keinen Schaden anrichten.
5. Schwierigkeiten bei der granulären Zugriffskontrolle
Manchmal hat man auf bestimmte Datensätze einen sehr beschränkten Zugriff und praktisch können keine oder ganz wenige Benutzer vertrauliche Informationen sehen, wie zum Beispiel persönliche Informationen in Krankenakten (Name, E-Mail, Blutzucker usw.). Aber einige Daten (ohne "harte" Restriktionen) könnten theoretisch für Benutzer ohne Zugriff zu vertraulichen Teilen, beispielsweise für medizinische Forscher, hilfreich sein. Dennoch sind alle nützlichen Inhalte vor ihnen versteckt. Und hier beginnen wir das Gespräch vom granulären Zugriff. Auf diese Weise können Benutzer auf die benötigten Datensätze zugreifen, aber nur diejenigen Informationen ansehen, die sie sehen dürfen.
Der Haken besteht darin, dass es schwierig ist, einen solchen Zugriff bezüglich Big Data bereitzustellen und zu steuern, nur weil Big-Data-Technologien ursprünglich ohne diese Funktion erstellt sind. Im Allgemeinen werden die Teile der benötigten Datensätze, die Benutzer sehen dürfen, in ein separates Big Data Warehouse kopiert und bestimmten Benutzergruppen als neues "Ganzes" bereitgestellt. Für eine medizinische Forschung wird beispielsweise nur die medizinische Information (ohne Namen, Adressen usw.) kopiert. Allerdings wächst die Menge von Ihrem Big Data auf diese Weise noch schneller. Andere komplexe Lösungen von granulären Zugriffsproblemen können ebenfalls die Systemleistung und -wartung beeinträchtigen.
6. Probleme mit der Datenherkunft
Die Herkunft der Daten (Data Provenance) – oder historische Aufzeichnungen über Ihre Daten – erschwert die Situation noch mehr. Da es zu ihren Aufgaben gehört, die Quelle der Daten und alle damit durchgeführten Manipulationen zu dokumentieren, können wir uns nur vorstellen, wie gigantisch die Sammlung von Metadaten sein kann. Big Data selbst ist in seiner Größe nicht klein. Und jetzt stellen Sie sich vor, dass jedes Datenelement detaillierte Informationen über seine Herkunft und die Art und Weise, wie das beeinflusst wurde, enthält (was überhaupt schwer zu bekommen ist).
Momentan ist die Datenherkunft ein breites Problem im Big-Data-Umfeld. Aus Sicherheitsgründen ist es wichtig, weil:
- Nicht autorisierte Änderungen an Metadaten können zu falschen Datensätzen führen, die es schwierig machen, benötigte Informationen zu finden.
- Nicht rückverfolgbare Datenquellen können ein riesiges Hemmnis sein, um die Wurzeln von Sicherheitsverletzungen und der Generierung von falschen Daten zu finden.
7. Schnelle Evolution von NoSQL-Datenbanken und mangelnder Fokus auf Sicherheit
Dieser Punkt mag ganz positiv aussehen, obwohl er tatsächlich ein ernstes Problem darstellt. Jetzt sind NoSQL-Datenbanken ein beliebter Trend in der Big-Data-Wissenschaft. Und seine Popularität ist genau das, was Probleme verursacht.
Technisch gesehen, werden NoSQL-Datenbanken ständig mit neuen Funktionen verfeinert. Und genau wie wir am Anfang dieses Artikels erwähnt haben, wird die Sicherheit vernachlässigt und in den Hintergrund gedrängt. Es besteht allgemein die Hoffnung, dass die Sicherheit für Big-Data-Lösungen extern bereitgestellt wird. Aber oft wird es sogar auf dieser Ebene ignoriert.
8. Fehlende Sicherheitsaudits
Die Sicherheitsaudits von Big Data helfen Unternehmen, Einsichten in ihre Sicherheitslücken zu erhalten. Und obwohl es empfohlen wird, diese regelmäßig durchzuführen, wird diese Empfehlung in Wirklichkeit selten erfüllt. Die Arbeit mit Big Data bringt genug Herausforderungen und Sorgen mit, und ein Audit würde nur die Liste ergänzen. Außerdem macht der Mangel an Zeit, Ressourcen, qualifiziertem Personal oder Klarheit in den Sicherheitsanforderungen auf Unternehmensseite solche Audits noch unrealistischer.
Aber keine Angst bitte: alle Probleme sind lösbar
Ja, es gibt viele Sicherheitsprobleme und Bedenken hinsichtlich Big Data. Und das stimmt auch, dass sie ausschlaggebend sein können. Aber das heißt nicht, dass Sie Big Data sofort als Konzept verfluchen sollten und dass sich Ihre Wege nie wieder kreuzen werden. Nein. In erster Linie müssen Sie sorgfältig Ihren Einführungsplan für Big Data entwerfen, indem Sie der Sicherheit solche Aufmerksamkeit schenken, die sie verdient – die größte. Das kann eine schwierige Aufgabe sein, aber Sie können sich immer an professionelle Experten in Big-Data-Beratung wenden, um eine benötigte Lösung zu bekommen.