Was ist Big Data? Ein Modewort erklärt


Alex Bekker ist Leiter der Abteilung Data Analytics in ScienceSoft, einem Unternehmen für IT-Beratung und Softwareentwicklung. Alex hat mehrere Projekte in den Bereichen wie Business Intelligence, Big Data, Data Analytics geleitet und auch den Unternehmen geholfen, die Vorteile von Data Science und maschinellem Lernen zu nutzen. Zu seinen größten Projekten gehören: Big-Data-Analyse für die Musterendeckung in der Mediennutzung in mehr als 10 Ländern; die Analyse von Eigenmarken-Produkten für mehr als 18.500 Produzenten, BI für 200 Gesundheitszentren.
Seit den letzten Jahren fragt man bei allwissendem Google immer häufiger danach, wie Big Data zum Erfolg eines Unternehmens beitragen kann, welche Big-Data-Technologien am besten sind, welche Tools für Big Data Analytics zum Einsatz kommen und mehr. Es wurde bereits viel über Big Data geschrieben und gesagt, aber der Begriff selbst bleibt ungeklärt. Ehrlich gesagt kann eine weit verbreitete Definition "Big Data ist big" für uns kaum von Nutzen sein. Aus solch einem Ansatz ergibt sich eine andere Frage: welche Maßeinheit wird verwendet, um die Größe von Daten zu messen? 1 Terabyte, 1 Petabyte, 1 Exabyte oder mehr?
Unsere Experten in der Big-Data-Beratung bevorzugen, einen konsistenten Ansatz zu nutzen. In unserem Blogbeitrag möchten wir die Grundlagen teilen und definieren, was Big Data aufgrund seiner Schlüsselmerkmale ist.

Definition von Big Data
Als Big Data bezeichnen wir Daten, die zwei folgende Kriterien erfüllen:
Informationell: Im Gegensatz zu herkömmlichen Daten, die sich jederzeit ändern können (z. B. Bankkonten, Warenmenge in einem Lagerhaus), stellt Big Data ein Protokoll von Datensätzen dar, wo jeder Datensatz ein bestimmtes Ereignis beschreibt. (z. B. ein Kauf in einem Geschäft oder eine Webseitenansicht, ein Sensorwert zu einem bestimmten Zeitpunkt, ein Kommentar in sozialen Netzwerken). Die Ereignisdaten ändern sich aufgrund ihrer Beschaffenheit nicht.
Außerdem kann Big Data unvollständige Informationen und Fehler enthalten, deshalb ist Big Data eine schlechte Wahl für die Aufgaben, bei denen eine absolute Genauigkeit entscheidend ist. Es macht also wenig Sinn, Big Data für Buchhaltung zu verwenden. Big Data ist jedoch statistisch korrekt und kann ein klares Verständnis von Gesamtbild, Trends und Abhängigkeiten vermitteln. Ein weiteres Beispiel aus der Finanzwelt: mithilfe von Big Data können Marktrisiken basierend auf einer Analyse von Kundenverhalten, Branchen-Benchmarks, Produktportfolio-Performance, Zinsentwicklung, Rohstoffpreisänderungen usw. identifiziert und gemessen werden.
Technisch: Big Data hat ein Volumen, das eine parallele Verarbeitung und einen speziellen Speicheransatz erfordert: ein Computer (oder ein Knoten, wie IT-Gurus es nennen) reicht nicht aus, um diese Aufgaben auszuführen - wir brauchen viele Computer, gewöhnlich von 10 bis 100.
Außerdem erfordert eine Big-Data-Lösung Skalierbarkeit. Um dem ständig wachsenden Datenvolumen gerecht zu werden, müssen wir bei jeder Erhöhung der Datenmenge keine Änderungen an der Software vornehmen. Falls das passiert, setzen wir nur mehr Knoten ein, und Daten werden automatisch dazwischen neu verteilt.
Branchenübergreifende Beispiele von praktischen Big-Data-Anwendungen
Lassen Sie uns über die Definition hinausgehen und einige anschauliche Beispiele betrachten, um besser zu verstehen, was Big Data ist. Wir haben diese Beispiele klassifiziert, um Big-Data-Anwendungen in verschiedenen Branchen zu zeigen.
Kundenanalyse
Um eine 360-Grad-Kundensicht zu schaffen, müssen Einzelhändler eine Fülle von Daten sammeln, speichern und analysieren. Je mehr Datenquellen sie verwenden, desto vollständiger wird das Bild. Das heißt, bei jedem von ihren über 10 Mio. Kunden können sie fünf Arten von Daten analysieren:
- Demografische Daten (dieser Kunde ist eine Frau, 35 Jahre alt, hat zwei Kinder usw.)
- Transaktionsdaten (die Produkte, die sie jedes Mal kauft, die Zeit zum Einkauf usw.)
- Daten über Online-Verhalten (die Produkte, die mam beim Online-Einkauf in ihren Warenkorb legt)
- Daten aus den von Kunden geschriebenen Texten (Kommentare über den Händler, die diese Frau im Internet hinterlässt)
- Angaben zur Nutzung eines Produkts / einer Dienstleistung (Rückmeldung über die Qualität der bestellten Ware, die Liefergeschwindigkeit usw.).
Kundenanalysen sind für Händler und Kunden gleichermaßen vorteilhaft. Die ersteren können ihr Produktportfolio anpassen, um die Kundenbedürfnisse besser zu erfüllen und effiziente Marketingaktivitäten zu organisieren. Die Letzteren können beliebte Produkte, relevante Aktionen und personalisierte Kommunikation genießen.
Analytics in der Industrie
Um teure Stillstandszeiten zu vermeiden, die alle zugehörigen Prozesse betreffen, können die Hersteller Sensordaten verwenden, um proaktive (d.h. vorausschauende) Wartungsmaßnahmen zu treffen. Stellen Sie sich vor, dass das analytische System Sensordaten für mehrere Monate sammelt und analysiert, um eine Geschichte von Beobachtungen zu bilden. Basierend auf diesen historischen Daten hat das System eine Reihe von Mustern identifiziert, die wahrscheinlich zu einem Maschinenausfall führen. Zum Beispiel erkennt das System, dass das Bild, das die Temperatur- und Lastsensoren zeigen, ähnlich der Situation vor dem Ausfall № 3 ist, und es benachrichtigt das Wartungsteam, die Maschine zu überprüfen.
Es ist wichtig zu erwähnen, dass vorbeugende Wartung nicht das einzige Beispiel dafür ist, wie die Hersteller Big Data nutzen können. In diesem Artikel finden Sie eine detailierte Beschreibung von anderen realen Big-Data-Anwendungsfällen.
Analytics von Business-Prozessen
Unternehmen nutzen auch Big-Data-Analysen, um die Leistung ihrer Remote-Mitarbeiter zu überwachen und die Effizienz der Prozesse zu verbessern. Nehmen wir als Beispiel den Transport. Die Unternehmen können die Telemetriedaten, die von jedem Lkw in Echtzeit kommen, sammeln und speichern, um ein typisches Verhalten jedes Fahrers zu identifizieren. Sobald das Muster definiert ist, analysiert das System Echtzeitdaten, vergleicht sie mit dem Muster und signalisiert, wenn eine Nichtübereinstimmung vorliegt. Auf diese Weise kann das Unternehmen sichere Arbeitsbedingungen gewährleisten (weil sich die Fahrer erholen müssen, aber sie beachten manchmal die Regel nicht).
Betrugsprävention durch Analytics
Die Banken können ein ungewöhnliches Kartenverhalten in Echtzeit erkennen (wenn jemand anderes, nicht der Besitzer, die Karte benutzt) und verdächtige Aktivitäten blockieren oder diese zumindest verschieben, um den Besitzer zu benachrichtigen. Zum Beispiel, wenn der Benutzer versucht, Geld in China abzuheben, während er in Deutschland wohnt, bevor die Transaktion abgelehnt wird, kann die Bank die Informationen des Benutzers aus dem sozialen Netzwerk überprüfen - vielleicht ist er einfach im Urlaub. Außerdem kann die Bank überprüfen, ob dieser Benutzer Verbindungen zu betrugsbezogenen Konten oder Aktivitäten über alle anderen Kanäle hat.
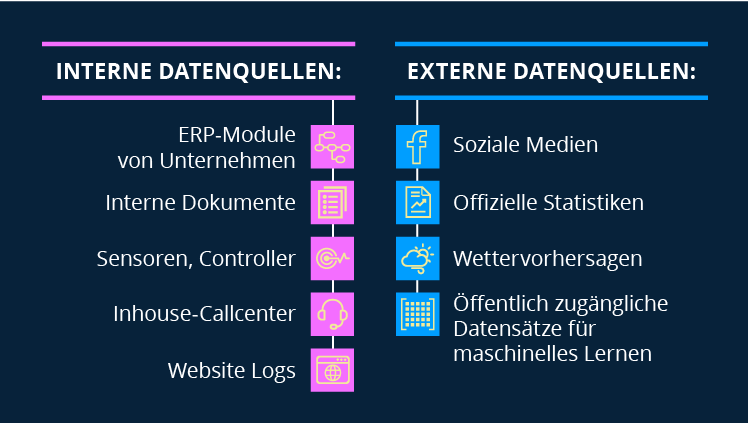
Externe und interne Quellen von Big Data
Es gibt zwei Kategorien von Big-Data-Quellen: interne und externe. Lassen wir uns sie genauer anschauen.
Wenn ein Unternehmen Daten generiert, besitzt und verwaltet, sind das interne Daten. Als externe Daten bezeichnet man öffentliche oder außerhalb des Unternehmens generierte Daten; das Unternehmen kann sie entsprechend weder besitzen noch verwalten. Betrachten wir einige selbsterklärende Beispiele für Datenquellen.
Autonomes System oder ein Teil der traditionellen BI?
Big Data kann sowohl als Teil der traditionellen BI als auch in einem unabhängigen System verwendet werden. Wenden wir uns wieder den Beispielen zu. Ein Unternehmen analysiert Big Data, um Verhaltensmuster jedes Kunden zu identifizieren. Basierend auf diesen Erkenntnissen ordnet er die Kunden mit ähnlichen Verhaltensmustern zu einem bestimmten Segment zu. Schließlich verwendet ein traditionelles BI-System Kundensegmente als weiteres Attribut für das Berichterstattung. Beispielsweise können die Benutzer Berichte erstellen, die den Umsatz pro Kundensegment oder ihre Reaktion auf eine aktuelle Werbeaktion anzeigen.
Ein anderes Beispiel: Stellen Sie sich eine E-Commerce-Website vor, die mit Hilfe vom analytischen System die Präferenzen jedes Benutzers durch die Überwachung der Produkte identifiziert, die sie kaufen oder an denen sie interessiert sind (je nach Zeitaufwand auf einer Produktseite). Aufgrund dieser Informationen empfiehlt das System "das-könnte-Ihnen-auch-gefallen"-Produkte. Hier funktioniert Big Data als unabhängiges System.
Big-Data-Technologien im Überblick:„ gut zu wissen“ Namen und Begriffe

In der Welt von Big Data wird die "eigene Sprache" genutzt. Es lohnt sich einige Namen und Begriffe kennenzulernen, um diese Sprache zu verstehen:
- Cloud ist die Bereitstellung von Computing-Ressourcen bei Bedarf auf der Basis "Pay-for-Use". Dieser Ansatz wird häufig in Big Data verwendet, weil letzteres eine schnelle Skalierbarkeit erfordert. Zum Beispiel kann ein Administrator mit wenigen Klicks 20 Computer hinzufügen.
- Hadoop ist ein Framework zur verteilten Speicherung großer Datenmengen und paralleler Datenverarbeitung. Es zerteilt eine große Portion von Daten zuerst in viele kleinere Teile, die parallel auf verschiedenen Datenknoten (Computern) verarbeitet werden, und sammelt die Ergebnisse automatisch über mehrere Knoten, um ein einzelnes Ergebnis zurückzugeben.
- HDFS ist Hadoop Distributed File System, das ermöglicht, mehrere Dateien gleichzeitig zu speichern und zu adressieren.
- Apache Spark ist ein Framework für die parallele In-Memory-Datenverarbeitung, das eine nahezu Echtzeit-Analyse ermöglicht. Ein analytisches System kann beispielweise identifizieren, dass ein Besucher eine lange Zeit auf bestimmten Produktseiten verbracht, aber dabei kein Produkt nicht in den Warenkorb gelegt hat. Um einen Kauf zu motivieren, kann das System einen Gutschein für die entsprechenden Produkte anbieten.
Jetzt wissen Sie, was Big Data ist. Oder?
Um diese Frage zu benatworten, haben unsere Big-Data-Berater ein kurzes Quiz erstellt. Es hilft Ihnen zu überprüfen, wie viel Sie über Big Data gelernt haben:
- Welche Art der Datenverarbeitung benötigt Big Data?
- Ist Big Data 100% zuverlässig und genau?
- Wenn Sie eine einzigartige Kundenerfahrung schaffen möchten, welche Art von Big Data Analytics benötigen Sie?
- Nennen Sie mindestens drei externe Big-Data-Quellen.
- Gibt es Ähnlichkeiten zwischen Hadoop und Apache Spark?
Gut gemacht! Wir hoffen, dass der Artikel hilfreich für Sie war und dass Sie das Quiz nach dem Lesen für leicht gehalten haben.