Alternative Ansätze zur Implementierung von Ihrem Data Lake


Iryna ist Forscherin in Data Analytics bei ScienceSoft, einem IT-Beratungs- und Softwareentwicklungsunternehmen mit Hauptsitz in McKinney, Texas. Mit einem Fokus auf Business Intelligence, Big Data und Data Science untersucht Iryna Trends und Technologien in der Welt der Datenanalyse sowie wichtige Herausforderungen und Lösungen.
Hat sich Ihr Unternehmen entschlossen, einen Data Lake (deutsch „Datensee“) für Ihr Big Data zu implementieren? Auf alle Fälle ist das eine spannende und gute Nachricht! Allerdings liegen noch schwierige Zeiten vor Ihnen, weil Sie so viele grundlegende Fragen klären und beantworten müssen. In dieser Etappe sind Sie höchstwahrscheinlich an einer Architektur von Data Lake und dem erforderlichen Technologie-Stack interessiert. Um Ihre Reise reibungslos und komfortabel zu machen, haben unsere Big-Data-Berater einen Überblick über alternative Implementierungsansätze erstellt.
Zonen in einem Data Lake
Ein Data Lake kann aus mehreren Zonen bestehen: einer Landing Zone (auch als Transient Zone oder Übergangszone bezeichnet), einer Staging Zone und einem analytischen Sandbox. Von allen genannten Zonen ist nur die Staging Zone obligatorisch, alle anderen sind optional. Um herauszufinden, wofür jede Zone steht, werfen wir einen genaueren Blick darauf.
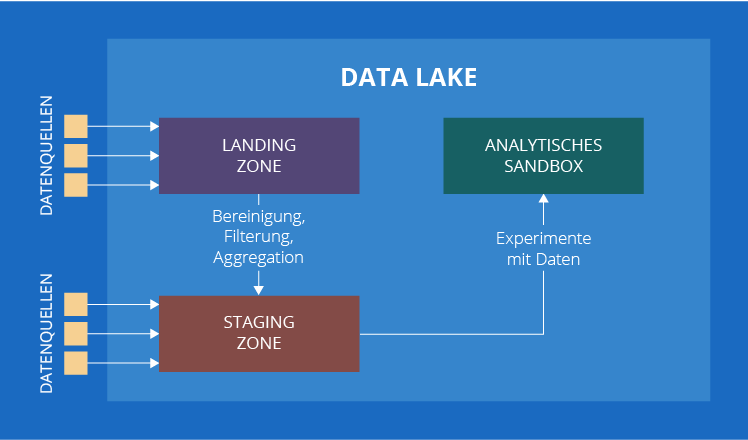
1. Landing Zone
Hierher kommen die Daten (strukturiert, unstrukturiert und halbstrukturiert), die bereinigt und/oder gefiltert werden müssen. Zum Beispiel sammeln Sie IoT-Daten von Sensoren. Wenn einer der Sensoren ungewöhnlich hohe Werte sendet, während die anderen Sensoren, die denselben Parameter messen, nichts Ungewöhnliches registriert haben, markiert eine in dieser Zone eingesetzte Verarbeitungsengine die Werte als fehlerhaft.
2. Staging Zone
Es gibt zwei Möglichkeiten, wie Daten in die Staging Zone geraten. Erstens können sie aus der Landing Zone kommen (falls diese vorhanden ist), wie die Sensordaten aus unserem vorherigen Beispiel. Zweitens können wir Daten, die keine Vorverarbeitung erfordern, von anderen internen oder externen Datenquellen beziehen. Kundenkommentare in sozialen Netzwerken sind ein gutes Beispiel, um diesen Fall zu veranschaulichen.
3. Analytisches Sandbox
Das ist die Zone für Experimente mit Daten, die von Datenanalysten durchgeführt werden. Es unterscheidet sich von der Analytik, die wir uns normalerweise vorstellen, weil ihre gefundenen Ergebnisse (wenn überhaupt) nicht direkt von Unternehmen verwendet werden. Übrigens haben wir dieses „wenn überhaupt“ bewusst angegeben. Es kommt ziemlich oft vor, dass Analysten einige Modelle oder Algorithmen in Bezug auf Rohdaten anwenden (die auch mit den Daten aus einem Big-Data-Warehouse oder aus anderen internen oder externen Datenquellen verbunden sein können) und keine wertvollen Ergebnisse erhalten. Für die explorative Datenanalyse ist das normal.
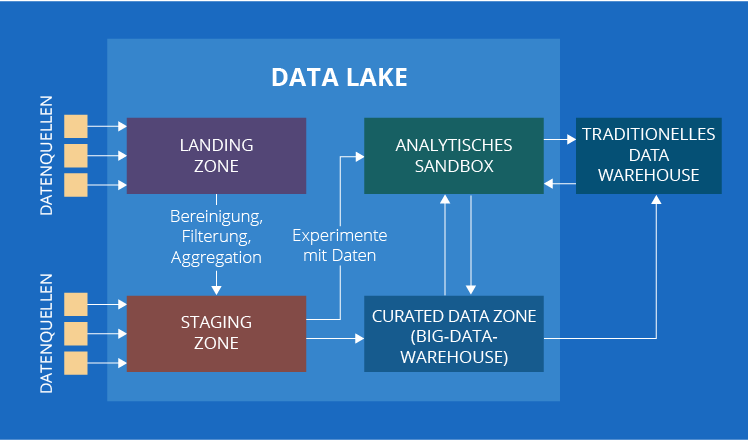
4. Und noch eine Zone kommt in Frage – Curated Data Zone
Inzwischen hätte unsere Liste vorbei sein sollen, wenn es nicht einen kleinen Haken gegeben hätte. In einigen Quellen können Sie auf eine weitere Komponente eines Data Lake – Curated Data Zone – stoßen. Das ist die Zone mit organisierten Daten, die für die Datenanalyse bereit sind.
Es gibt unterschiedliche Meinungen darüber, ob die Curated Data Zone als Teil eines Data Lake betrachtet werden soll. Obwohl beide Ansätze sinnvoll sind, sind wir der Meinung, dass das eher nicht der Fall sein sollte. Bevor wir jedoch die Argumente zur Unterstützung unseres Standpunkts vorbringen, lassen wir uns die Begriffe in Ordnung bringen.
Sehen Sie sich noch einmal die Beschreibung der Curated Data Zone an. Sieht sie nicht ähnlich aus wie ein gutes altes traditionelles Data Warehouse? Das stimmt durchaus! Der einzige Unterschied besteht darin, dass ein herkömmliches Data Warehouse nur mit traditionellen Daten arbeitet und die Curated Data Zone mit traditionellen Daten und Big Data. Um den Einfluss von Datentypen zu neutralisieren, erweitern wir den Namen auf Big-Data-Warehouse.
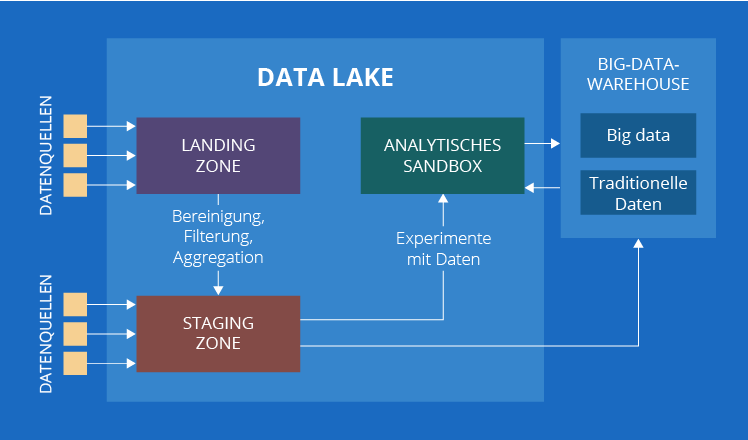
Jetzt, nachdem wir klargestellt haben, dass die Curated Data Zone auch als Big-Data-Warehouse bezeichnet werden kann, wollen wir besprechen, warum wir der Ansicht sind, dass sie sich außerhalb eines Data Lake befindet. Die in einem Big-Data-Warehouse gespeicherten Daten unterscheiden sich grundlegend von den Daten in einer beliebigen Zone eines Data Lake – sie sind besser organisiert und liefern bereits Erkenntnisse für Geschäftsanwender.
Außerdem wird die Unterscheidung zwischen traditionellen Daten und Big Data in dieser Phase der Datenreise unkritisch. Beide Typen koexistieren friedlich und ergänzen sich gegenseitig, um ihren Zweck zu erfüllen – um Geschäftsanwendern Einblicke zu verschaffen. Um beispielsweise Kunden zu segmentieren, können Sie eine Vielzahl von Daten analysieren, zu denen Big Data wie die Surfhistorie eines Kunden auf der Website und die Aktivitäten in mobilen Apps für Kunden gehören. Später können Sie Berichte zu Umsatz oder Gewinn pro Kundensegment erstellen, was reine traditionelle Business Intelligence darstellt.
Wenn Sie sich wundern, warum ein Big-Data-Warehouse manchmal als Teil eines Data Lake betrachtet wird, haben wir auch eine Erklärung dafür. Die meisten Unternehmen, die sich für Big Data entscheiden, verfügen bereits über ein traditionelles Data Warehouse. Daher entscheiden sie sich normalerweise dafür, ihre analytische Lösung durch den Aufbau eines Data Lake zu erweitern. In diesem Fall bleibt ein traditionelles Data Warehouse ein herkömmliches wichtiges Element und alle neuen Elemente sind mit einem Data Lake verbunden.
Technische Alternativen zur Implementierung von Ihrem Data Lake
Die Liste der Technologien zur Speicherung von Big Data umfasst eine Vielzahl von Namen: Hadoop Distributed File System, Apache Cassandra, Apache HBase, Amazon S3, MongoDB sind nur einige der beliebtesten. Zweifellos wird man bei der Auswahl eines Technologie-Stacks für einen Data Lake zuerst an die Technologien denken, die die Speicherung von Big Data ermöglichen. Das ist eine richtige Grundlage, obwohl Sie sich auch über die Verarbeitung Gedanken machen müssen. Deshalb sollte die Liste der Technologien mit Apache Storm, Apache Spark, Hadoop MapReduce usw. erweitert werden. Kein Wunder, wenn Sie verwirrt sind, welche Kombination die beste Wahl für Ihren Data Lake ist!
Bestimmende Faktoren zur Auswahl eines Technologie-Stacks
Obwohl jeder Fall individuell ist, haben wir fünf wichtige Faktoren zusammengefasst, die zum Ausgangspunkt Ihrer Diskussion mit Ihren Big-Data-Beratern werden:
- Daten, die gespeichert und verarbeitet werden müssen: Big Data im IoT, Texte, Video usw.
- Erforderliche Architektur eines Data Lake
- Skalierbarkeit
- In-Cloud- oder On-Premises-Lösung
- Integration mit den vorhandenen Komponenten der IT-Architektur.
Gibt es eine führende Technologie?
Gemäß der allgemeinen Big-Data-Beratungspraxis ist Hadoop Distributed File System (HDFS) die beliebteste unter der Vielzahl möglicher Technologien für einen Big Data Lake. Die Gründe sind wie folgt:
- HDFS ist extrem gut in der Handhabung der Datenvielfalt in einem Big Data Lake. Big Data im IoT, Video-, Audio- und Textdateien – mit HDFS können Sie jeden Datentyp speichern. Wenn wir vergleichen, ist Apache Cassandra gut zum Speichern von Big Data im IoT, während MongoDB – von Texten.
- HDFS unterstützt eine Vielzahl von Verarbeitungstechniken. HDFS ist eines der Elemente des Apache Hadoop-Ökosystems, das mehrere andere Komponenten wie Hadoop MapReduce, Hadoop YARN, Apache Hive, Apache HBase usw. enthält. Da sie zur selben Familie gehören, ist es selbstverständlich, dass jede davon sehr kompatibel mit HDFS ist. Außerdem hat sich HDFS als sehr kompatibel mit Apache Spark erwiesen, was die Möglichkeit bietet, Big Data schnell zu verarbeiten.
Natürlich können Sie auch andere Technologien in Betracht ziehen, um einen Data Lake zu implementieren. Ein wichtiges Kriterium ist hier das Wissen, wie man seine Grenzen herumgehen kann. Zum Beispiel können Sie nach dem Vergleich von HDFS und Cassandra entscheiden, einen Data Lake auf letzterem zu betreiben. Warum nicht, wenn Sie einen Data Lake ausschließlich als Staging Zone für IoT-Daten planen und wissen, wie Sie in Cassandra fehlende Joins kompensieren können?
Data Lake als Service
Amazon Web Services, Microsoft Azure, Google Cloud Platform haben ein entsprechendes Angebot – ein Data Lake als Service. Tatsächlich wäre es für einen Neuling schwierig, die Unterschiede zwischen diesen drei Angeboten zu erkennen. Im Wesentlichen sind sie sich ziemlich ähnlich: Sie benötigen ein AWS/Azure/GCP-Konto, Ihre Daten und die Bereitschaft, den Dienst zu bezahlen. Im Gegenzug erhalten Sie eine vordefinierte Reihe von Technologien, die in der Cloud bereitgestellt werden und Wartungskopfschmerzen beseitigen. Der Technologie-Stack hinter der Szene gilt als selbstverständlich, obwohl die Funktionen, die sie ausführen, gewöhnlich sind: Speicherung, Verarbeitung, Streaming und Analytik. Wir planen, einen einzelnen Blogbeitrag zu schreiben, der die Vor- und Nachteile dieser drei Angebote aufzeigt. Also bleiben Sie dran.
Lassen wir uns kurz zusammenfassen
Was sind die Hauptfaktoren, die die Wahl der Technologien für einen Data Lake beeinflussen?
- Die Arten von Daten, die gespeichert und verarbeitet werden müssen
- Die Zonen eines Data Lake (nur eine Staging Zone oder eine Landing Zone und ein analytisches Sandbox)
- Skalierbarkeit
- In-Cloud- oder On-Premises-Lösung
- Integration mit den vorhandenen Komponenten der IT-Architektur.
Sollten wir uns am Ende für nur eine Technologie entscheiden?
Nein, Sie sollten nicht. Unsere Praxis zeigt, dass Data-Lake-Lösungen implementiert werden, indem sie auf mehreren Technologien basieren. Um eine Geschäftsaufgabe zu lösen, können Big-Data-Berater für jede Zone eines Data Lake eine separate Technologie auswählen.
Gibt es eine bevorzugte Technologie für einen Data Lake?
Hadoop Distributed File System ist die beliebteste, aber nicht die einzige verfügbare Technologie. Seien Sie jedoch vorsichtig und beruhen Sie Ihren Wahl auf Ihren Geschäftszielen und dementsprechend auf den Anforderungen an Ihre zukünftige analytische Lösung und nicht auf der Popularität eines Frameworks.
Wenn ich einen Data Lake nicht von Grund auf neu erstellen möchte, kann ich mich für eine gebrauchsfertige Lösung entscheiden?
Ja, Sie können. Amazon Web Services, Microsoft Azure und Google Cloud Platform bieten einen Data Lake als Service an. Was von Ihnen benötigt wird: Ihre Daten und Ihre Abonnement- und Servicegebühren. Und Sie erhalten einen Data Lake, der einfach und schnell zu implementieren ist.