Cassandra vs. HBase: Zwillinge oder nur Fremde, die ähnlich aussehen?


Alex Bekker ist Leiter der Abteilung Data Analytics in ScienceSoft, einem Unternehmen für IT-Beratung und Softwareentwicklung. Alex hat mehrere Projekte in den Bereichen wie Business Intelligence, Big Data, Data Analytics geleitet und auch den Unternehmen geholfen, die Vorteile von Data Science und maschinellem Lernen zu nutzen. Zu seinen größten Projekten gehören: Big-Data-Analyse für die Musterendeckung in der Mediennutzung in mehr als 10 Ländern; die Analyse von Eigenmarken-Produkten für mehr als 18.500 Produzenten, BI für 200 Gesundheitszentren.

Apache Cassandra und Apache HBase sind wie zwei Fremde, denen man auf der Straße begegnet und die man für Zwillinge hält. Man kennt sie wirklich nicht, aber ihre ähnlichen Größe, Kleidung und Frisuren lassen keine Unterschiede zwischen ihnen sehen. Nachdem man sie jedoch näher betrachtet, versteht man, dass die beiden nur aus der Entfernung identisch aussahen.
Mit zahlreichen Ähnlichkeiten, dass z.B. die beiden den NoSQL Wide Column Stores (spaltenorientierten Datenbanken) zugeordnet sind und ihren Ursprung von BigTable nehmen, unterscheiden sich Cassandra und HBase in einigen Aspekten. Zum Beispiel hat HBase keine Abfragesprache, was bedeutet, dass Sie mit der JRuby-basierten HBase-Shell arbeiten müssen und zusätzliche Technologien wie Apache Hive, Apache Drill oder etwas Ähnliches benötigen. Während sich Cassandra ihrer eigenen Sprache CQL (Cassandra Query Language) rühmen kann, die Cassandra-Praktiker am hilfreichsten finden.
Die Liste der Unterschiede und Gemeinsamkeiten endet hier nicht. Also schauen wir uns HBase und Cassandra genauer an, um sie alle zu finden.
1. Datenmodell
HBase
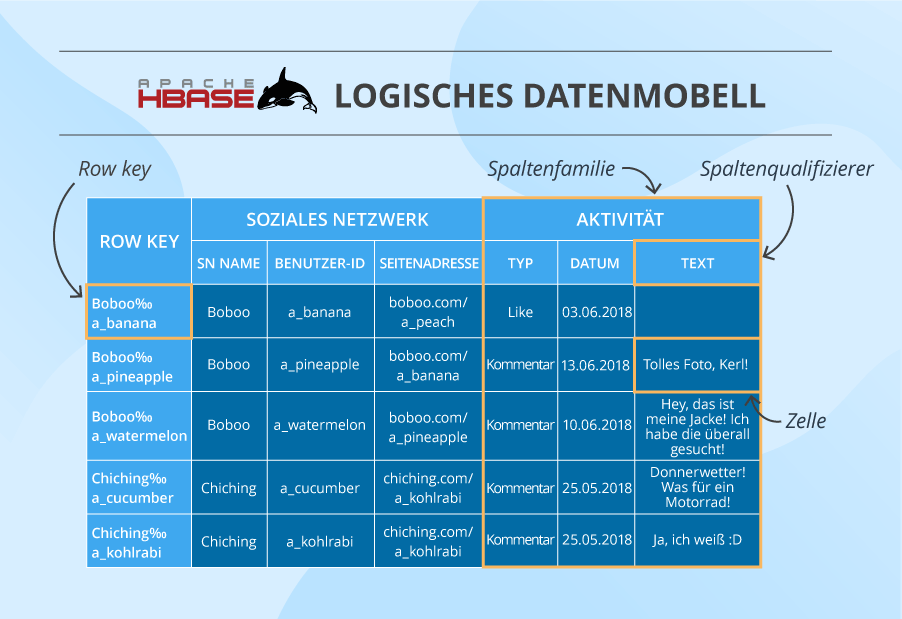
Hier haben wir eine Tabelle. Sie besteht aus Zellen, die nach Row Keys (Zeilenschlüsseln) und Spaltenfamilien organisiert sind. Manchmal verfügt eine Spaltenfamilie (SF) über eine Reihe von Column Qualifiers (Spaltenqualifizierern), um die Daten in einer SF besser zu organisieren.
Eine Zelle enthält einen Wert und einen Zeitstempel. Und eine Spalte ist eine Ansammlung von Zellen unter einem gemeinsamen Column Qualifier und einer gemeinsamen SF.
Innerhalb einer Tabelle werden Daten durch einen aus einer Spalte bestehenden Row Key in lexikografischer Reihenfolge partitioniert, wobei lokal verwandte Daten nahe beieinander gespeichert werden, um die Leistung zu maximieren. Das Design des Zeilenschlüssels ist entscheidend und muss in dem vom Entwickler geschriebenen Algorithmus gründlich durchdacht sein, um eine effiziente Datensuche zu gewährleisten.
Cassandra
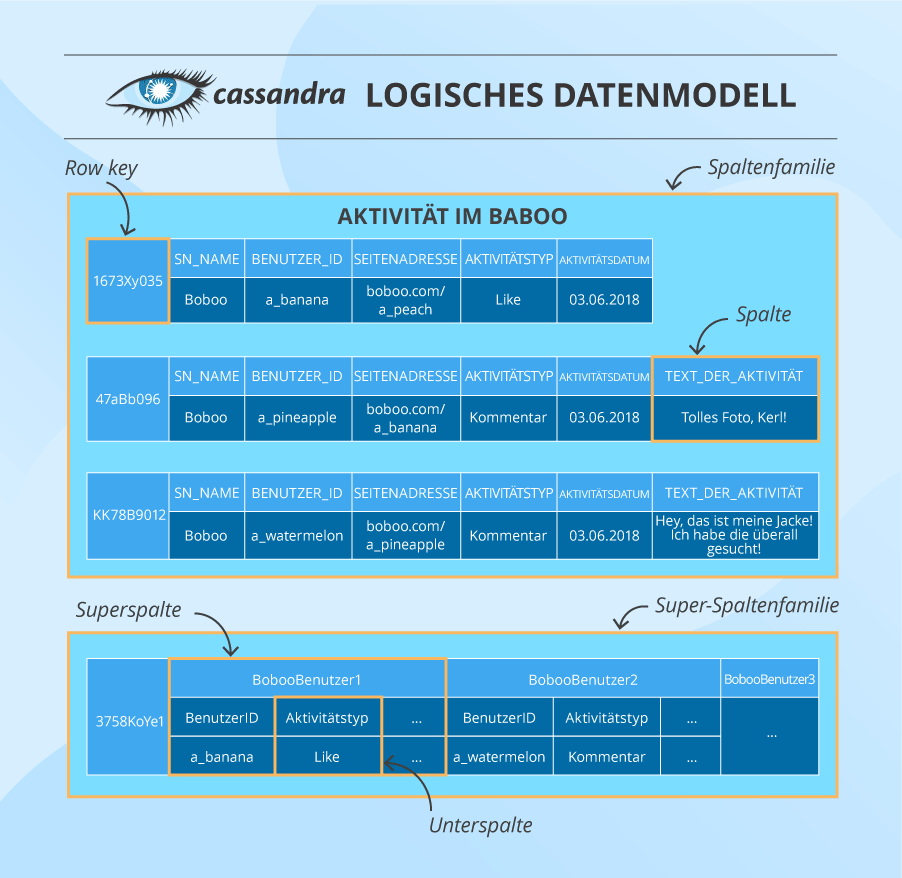
Hier haben wir eine Spaltenfamilie. Sie besteht aus Spalten, die nach Row Keys organisiert sind. Eine Spalte enthält einen Namen/Schlüssel, einen Wert und einen Zeitstempel. Zusätzlich zu einer normalen Spalte verfügt Cassandra auch über Superspalten, die zwei oder mehr Unterspalten enthalten. Solche Einheiten sind in Superspaltenfamilien gruppiert (obwohl diese selten verwendet werden).
Im Cluster werden Daten durch einen mehrspaltigen Primärschlüssel partitioniert, der einen Hashwert erhält, und an den Knoten, dessen Token numerisch größer als der Hashwert ist, gesendet werden. Darüber hinaus werden die Daten auch in eine zusätzliche Anzahl von Knoten geschrieben, die vom Replikationsfaktor abhängt, der von Cassandra-Experten festgelegt wird. Die Auswahl von zusätzlichen Knoten kann von ihrer physischen Position im Cluster abhängen.
HBase vs. Cassandra (Datenmodellvergleich)
Die Begriffe sind fast gleich, aber ihre Bedeutungen sind unterschiedlich. Beginnend mit einer Spalte: Eine Spalte von Cassandra ist eher einer Zelle in HBase ähnlich. Eine Spaltenfamilie in Cassandra ähnelt eher einer HBase-Tabelle. Und der Column Qualifier in HBase ist ähnlicher Art wie eine Superspalte in Cassandra, aber die letztere enthält mindestens 2 Unterspalten, während die erste – nur eine.
Außerdem erlaubt Cassandra, dass ein Primärschlüssel mehrere Spalten enthält, und HBase hat im Gegensatz zu Cassandra nur eine Spalte im Row Key und legt dem Entwickler die Last beim Entwurf eines Zeilenschlüssels auf. Außerdem besteht der Primärschlüssel von Cassandra aus einem Partitionsschlüssel und Clustering-Spalten, wobei der Partitionsschlüssel auch mehrere Spalten enthalten kann.
Trotz dieser "Konflikte" ist die Bedeutung beider Datenmodelle nahezu identisch. Sie haben keine Joins, weshalb sie topisch verwandte Daten zusammen gruppieren. Die beiden können keinen Wert in einer bestimmten Zelle/Spalte haben, was keinen Speicherplatz beansprucht. Die beiden müssen Spaltenfamilien während des Schema-Designs angeben und können diese im Nachhinein nicht ändern, während Spalten und Column Qualifiers flexibel sind und jederzeit geändert werden können. Aber vor allem eignen sich die beiden gut zum Speichern von Big Data.
2. Architektur
Cassandra hat eine masterlose Architektur, während HBase eine masterbasierte hat. Das ist der gleiche Unterschied in der Architektur wie zwischen Cassandra und HDFS.
Das bedeutet, dass HBase einen Single Point of Failure (einzelne Stelle des Scheiterns) hat, während Cassandra keinen hat. Ein HBase-Client kommuniziert wirklich direkt mit dem Slave-Server, ohne den Master zu kontaktieren, wodurch eine gewisse Arbeitszeit dem Cluster nach dem Ausfall des Masters eingeräumt wird. Aber das kann kaum mit dem immer verfügbaren Cassandra-Cluster konkurrieren. Also, wenn Sie sich keine Ausfallzeiten leisten können, ist Cassandra Ihre Wahl.
Um die Verfügbarkeit sicherzustellen, repliziert und dupliziert Cassandra Daten, was zu den Problemen der Datenkonsistenz führt. Dadurch ist Cassandra eine schlechte Wahl, wenn Ihre Lösung stark von der Datenkonsistenz abhängt, im Gegensatz zur stark konsistenten HBase. Da die letztere Daten nur an einen Ort schreibt und immer weiß, wo sie zu finden sind (die Datenreplikation erfolgt "extern" in HDFS).
Darüber hinaus unterstützt die Architektur von Cassandra sowohl die Datenverwaltung als auch die Datenspeicherung, während die HBase-Architektur nur für die Datenverwaltung konzipiert ist. HBase ist von Natur aus stark auf andere Technologien wie HDFS für Speicherung, Apache Zookeeper für das Server-Status-Management und Metadaten angewiesen. Und wiederum benötigt HBase zusätzliche Technologien, um Abfragen auszuführen.
3. Performance
-
Das Schreiben
Die auf dem Server durchgeführten Schreibvorgänge von Cassandra und HBase sind sehr ähnlich. Es gibt nur kleine Unterschiede: Namen für Datenstrukturen und die Tatsache, dass HBase im Gegensatz zu Cassandra gleichzeitig in das Log und den Cache nicht schreibt (das macht Schreibvorgänge langsamer).
Auf der höheren Architekturebene hat HBase noch mehr Nachteile:
1. Bevor der Client zum benötigten Server gelangt, muss er den ZooKeeper "fragen", welcher Server die Hbase:metatabelle hat, die Informationen über die Standorte aller Tabellen im Cluster enthält. Dann fragt der Client den die Metatabelle „besitzende“ Server, welcher Server die tatsächliche Tabelle speichert, zu der er schreiben muss. Und erst danach schreibt der Client die Daten an den benötigten Ort. Wenn solche Schreibvorgänge (und auch Lesevorgänge) häufig sind, wird diese Information natürlich zwischengespeichert. Wenn eine Tabellenregion jedoch auf einen anderen Server verschoben wird, muss der Client erneut die vollständige Runde ausführen. Und die Datenverteilung und -partitionierung in Cassandra basiert auf konsistentem Hashing, was viel klüger und schneller ist, als bei Hbase.
2. Sobald der In-HBase-Schreibvorgang endet (Daten im Cache werden auf den Datenträger ausgelagert), benötigt HDFS auch Zeit, um die Daten physisch zu speichern.
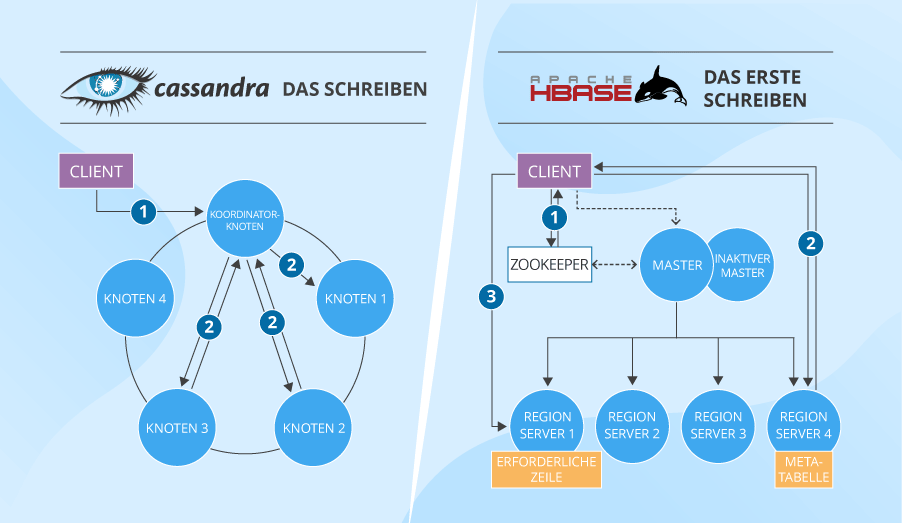
Darüber hinaus beweisen die wirklichen Messungen der Schreib-Performance von Cassandra ebenfalls (in einem Cluster aus 32 Knoten fast 326.500 Operationen pro Sekunde gegenüber 297.000 bei HBase), dass Cassandra bei Schreibvorgängen besser als HBase ist.
-
Das Lesen
Wenn Sie viele schnelle und konsistente Lesevorgänge benötigen (Zufallszugriff auf Daten und Scans), können Sie sich für HBase entscheiden. Da nur auf einem Server geschrieben wird, müssen die Datenversionen der verschiedenen Knoten nicht verglichen werden. HBase-Server haben auch nicht zu viele Datenstrukturen, die die Datenbank überprüfen muss, bevor sie Ihre Daten findet. Sie denken vielleicht, dass das Lesen in HBase ineffizient ist, weil die Daten tatsächlich in HDFS gespeichert sind, und HBase muss sie jedes Mal daraus herausholen. Aber HBase verfügt über einen Block-Cache, der alle häufig abgefragten HDFS-Daten hat, sowie über Bloom-Filter mit den ungefähren "Adressen" aller anderen Daten, was den Datenabruf beschleunigt. Im Grunde genommen ist das Indexsystem von HBase und HDFS vielschichtig, was wesentlich effizienter als die Indizes von Cassandra ist (lesen Sie unseren Artikel über die Leistung von Cassandra, um mehr über ihre Lesevorgänge zu erfahren).
Wenn Sie gelesen haben, dass Cassandra auch sehr gut beim Lesen ist, könnten Sie durch die Schlussfolgerung, dass HBase besser ist, verwirrt sein. Vor allem, wenn Sie diese Benchmarking-Erfahrung gesehen haben, laut der Cassandra 129.000 Lesevorgänge pro Sekunde verarbeitet, während HBases nur 8.000 (in einem Cluster aus 32 Knoten). Die Sache ist, diese Lesevorgänge sind zielgerichtet (basiert auf bekannten Primärschlüsseln), und dadurch eine Möglichkeit besteht, dass sie auch ziemlich inkonsistent sind. So verblassen große Zahlen von Cassandra, wenn wir über Scans und Konsistenz sprechen.
4. Sicherheit
Wie alle NoSQL-Datenbanken, haben HBase und Cassandra ihre Sicherheitsprobleme (das Hauptproblem ist, dass die Sicherung der Daten die Leistung beeinträchtigt und das System schwer und unflexibel macht). Aber es ist sicher zu sagen, dass beide Datenbanken über einige Funktionen zur Gewährleistung der Datensicherheit verfügen: Authentifizierung und Autorisierung in den beiden und Knoten-Knoten- und Client-Knoten-Verschlüsselung in Cassandra. HBase bietet seinerseits die dringend benötigten Mittel für die sichere Kommunikation mit anderen Technologien, auf die sie angewiesen ist.
Ein bisschen mehr Details:
Sowohl Cassandra als auch HBase bieten nicht nur eine Zugriffskontrolle über die ganze Datenbank, sondern auch ein gewisses Maß an Granularität. Cassandra ermöglicht den Zugriff auf Zeilenebene und HBase macht das sogar auf Zellenebene. Cassandra definiert Benutzerrollen und legt Bedingungen für diese Rollen fest, die später bestimmen, ob ein Benutzer bestimmte Daten sehen kann oder nicht. Während HBase eine umgekehrte "Bewegung" macht. Seine Administratoren weisen den Datensätzen ein Sichtbarkeit-Label zu und "erzählen" dann den Benutzern und Benutzergruppen, welche Label sie sehen können.
5. Anwendungsfälle
Nach zu urteilen, wie Cassandra und HBase ihre Datenmodelle organisieren, eignen sich die beiden sehr gut für Zeitreihendaten: Sensormessungen in IoT-Systemen, Website-Besuche und Kundenverhalten, Börsendaten usw. Sie speichern und lesen solche Werte gut. Außerdem ist die Skalierbarkeit die Eigenschaft, über die beide verfügen: Cassandra – über eine lineare, HBase – über eine lineare und modulare.
Wenn es jedoch darum geht, große Datenmengen zu scannen, um eine kleine Anzahl von Ergebnissen zu finden, ist HBase besser, weil sie keine Datenduplikationen hat. Zum Beispiel wird HBase auch aus diesem Grund angewendet, um Textanalysen zu bearbeiten (basierend auf Webseiten, Beiträgen aus sozialen Netzwerken, Wörterbüchern usw.). Außerdem kann HBase den Plattformen für das Datenmanagement und einfachen Datenanalysen (Zählen, Summieren und so weiter; aufgrund seiner Coprozessoren in Java) gerecht werden.
Cassandra eignet sich gut für die Aufnahme von großen Datenmengen, weil sie eine effiziente schreiborientierte Datenbank darstellt. Damit können Sie einen zuverlässigen und verfügbaren Datenspeicher erstellen. Darüber hinaus können Sie mit Cassandra Datencenter in verschiedenen Ländern erstellen und synchronisieren. Wenn Sie Cassandra mit Spark benutzen, können Sie außerdem eine gute Scan-Leistung erzielen.
Aber der Hauptunterschied zwischen der Anwendung von Cassandra und HBase in realen Projekten ist der folgende. Cassandra ist gut für immer aktive Web- oder mobile Apps und Projekte mit komplexen und/oder Echtzeit-Analysen. Wenn es keine Eile für Analyseergebnisse gibt (z. B. Experimente in einem Data Lake durchführen oder maschinelle Lernmodelle erstellen), ist HBase möglicherweise eine gute Wahl. Vor allem, wenn Sie bereits in die Infrastruktur und Spezialisten in Hadoop investiert haben.
Cassandra vs. HBase – eine Zusammenfassung
Cassandra ist eine "selbstständige" Technologie für die Datenspeicherung und -verwaltung, während HBase nicht so ist. Letzteres war als Werkzeug für die zufällige Dateneingabe/-ausgabe für HDFS gedacht, deshalb sind alle seine Daten dort gespeichert. Außerdem verwendet HBase ZooKeeper als Server-Status-Manager und den "Guru", der weiß, wo alle Metadaten sind (um sofortige Cluster-Ausfälle zu vermeiden, wenn der Metadaten-enthaltende Master ausfällt). Folglich ist ein komplexes interdependentes System von HBase schwieriger zu konfigurieren, zu sichern und zu warten.
Cassandra ist für die Schreibvorgänge geeignet, während HBase gut für intensive Lesevorhänge ist. Die Schwachstelle von Cassandra ist die Datenkonsistenz, während der Schmerz von HBase die Datenverfügbarkeit ist, obwohl die beiden versuchen, die negativen Folgen dieser Probleme zu mildern. Außerdem stehen die beiden nicht durch, häufig Daten zu löschen und zu aktualisieren.
Also, Cassandra und HBase sind bestimmt keine Zwillinge, sondern nur zwei Fremde mit einer ähnlichen Frisur. Um zwischen den beiden zu wählen, sollten Sie Ihre Aufgaben gründlich analysieren. Versuchen Sie auch danach, einen Weg zu finden, die Schwachstellen der Datenbank zu stärken, ohne die Leistung zu beeinträchtigen.