Erstellung einer Big-Data-Lösung, die half, Muster der Mediennutzung in mehr als 10 Ländern zu entdecken
Kunde
Der Kunde ist ein führendes Marktforschungsunternehmen, das Muster der Mediennutzung in mehr als 10 Ländern analysiert.
Herausforderung
Obwohl der Kunde ein robustes Analysesystem hatte, glaubte er, dass er nicht in der Lage sein würde, die zukünftigen Anforderungen des Unternehmens zu erfüllen. Angesichts dieser Situation hielt der Kunde nach einer zukunftsorientierten innovativen Lösung Ausschau. Das zukünftige System soll der stetig wachsenden Datenmenge gerecht werden, Big Data schneller analysieren und auf Basis der Analyseergebnisse Einblicke in die Muster der Mediennutzung geben.
Nachdem die zukünftige Systemarchitektur gewählt wurde, suchte der Kunde ein hochqualifiziertes und erfahrenes Team für die Umsetzung des Projekts. Zufrieden mit einer langjährigen Zusammenarbeit mit ScienceSoft, wandte sich der Kunde an unsere Berater, um die gesamte Migration vom alten Analysesystem in ein neues System durchzuführen.
Lösung
Während des Projekts arbeiteten die BI-Architekten des Kunden eng mit den Experten von ScienceSoft in Bereich Big-Data-Beratung zusammen. Die ersteren entwarfen eine Idee, das letztere war für die Umsetzung verantwortlich.
Für das neue Analysesystem wählten die Architekten des Kunden folgende Frameworks:
- Apache Hadoop - für die Datenspeicherung;
- Apache Hive - für Datenaggregation, -abfrage und -analyse;
- Apache Spark - für die Datenverarbeitung.
Amazon Web Services und Microsoft Azure wurden als Cloud-Computing-Plattformen ausgewählt.
Auf Wunsch des Kunden wurden während der Migration das alte System und das neue System parallel betrieben.
Insgesamt umfasste die Lösung fünf Hauptmodule:
- Data Preparation
- Staging
- Data Warehouse 1
- Data Warehouse 2
- Desktop-Anwendung
Data Preparation
Das System wurde mit Rohdaten aus mehreren Quellen versorgt, z. B. TV-Einschaltquoten, Browserverlauf in Mobilgeräten, Daten über Website-Besuche und Umfragen. Damit das System mehr als 1.000 verschiedene Arten von Rohdaten (Archive, XLS-, TXT-Formate usw.) verarbeiten kann, besteht die Data Preparation aus den folgenden Phasen, die in Python programmiert sind:
- Datentransformation
- Data-Parsing
- Zusammenführung von Daten
- Laden von Daten in das System.
Staging
Apache Hive bildete das Herzstück dieses Moduls. Die Datenstruktur war zu diesem Zeitpunkt der Rohdatenstruktur ähnlich und hatte keine Verbindungen zwischen Befragten aus verschiedenen Quellen, z. B. TV und Internet.
Data Warehouse 1
Ähnlich wie der vorherige Block basiert auch dieser auf Apache Hive. Dort fand die Datenmapping statt. Zum Beispiel verarbeitet das System die Daten der Befragten aus Radio-, TV-, Internet- und Zeitungsquellen und verknüpfte Benutzer- ID aus verschiedenen Datenquellen gemäß den Mappingregeln. ETL für diesen Block wurde in Python geschrieben.
Data Warehouse 2
Mit Apache Hive und Spark als Kern garantierte der Block die Datenverarbeitung sehr schnellnach Geschäftslogik: Er berechnete Summen, Durchschnittswerte, Wahrscheinlichkeiten usw. Sparks DataFrames wurden verwendet, um SQL-Abfragen von der Desktop-Applikation zu verarbeiten. ETL wurde in Scala geschrieben. Außerdem ermöglicht Spark, dass Abfrageergebnisse gemäß den Zugriffsrechten, die die Benutzer des Systems erhalten haben, gefiltert werden.
Desktop-Anwendung
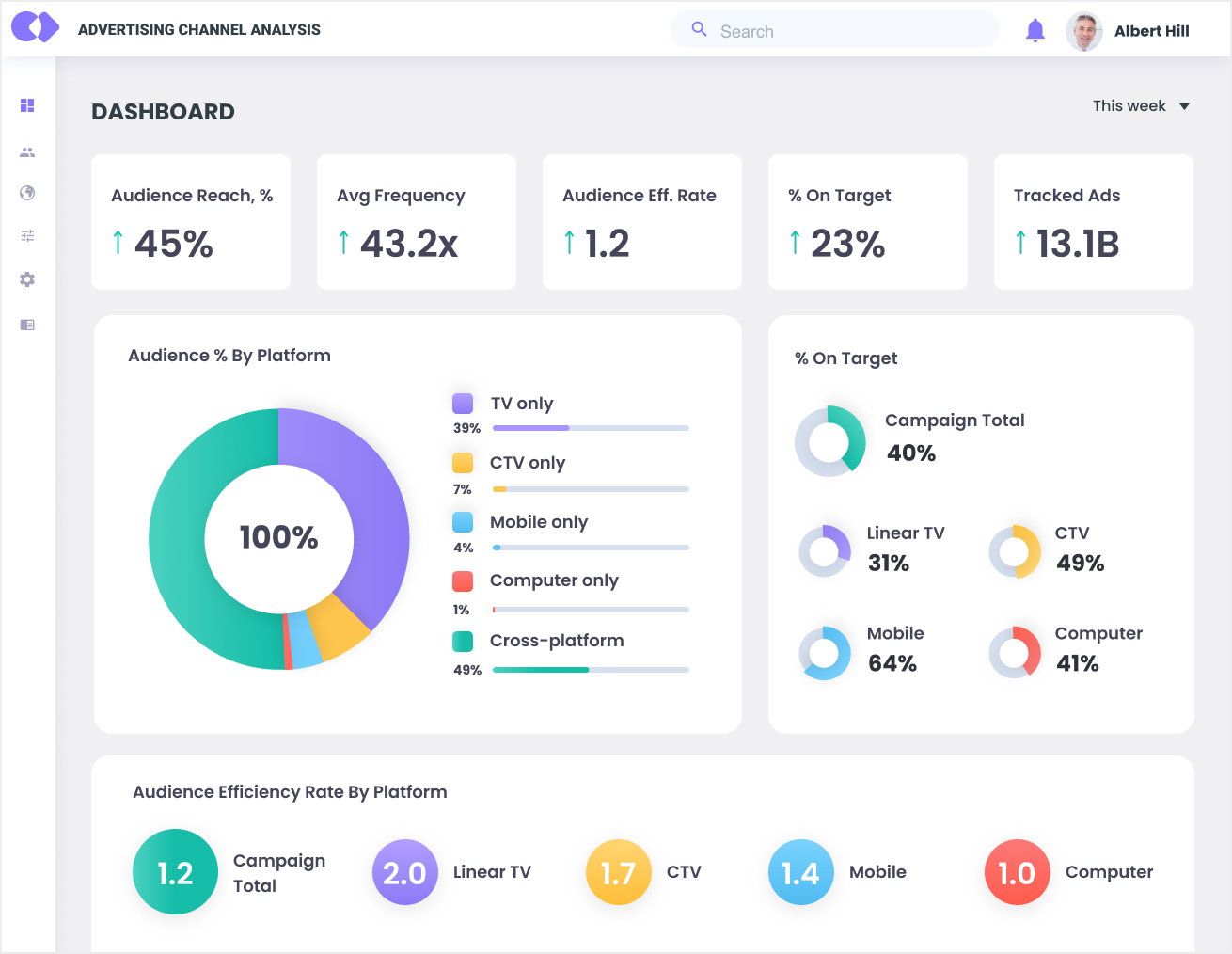
Das neue System ermöglichte eine Cross-Analyse von fast 30.000 Attributen und integrierte Kreuzungsmatrizen, die eine Datenanalyse aus mehreren Blickwinkeln für verschiedene Märkte ermöglichen. Zusätzlich zu Standardberichten, wie zum Beispiel Reach Pattern, Reach Ranking, verbrachte Zeit, Anteil der Zeit usw., konnte der Kunde Ad-hoc-Berichte erstellen. Nachdem der Kunde mehrere relevante Parameter ausgewählt hat (z. B. einen bestimmten TV-Kanal, eine Gruppe von Kunden, die Tageszeit), gab das System eine schnelle Antwort in Form von leicht verständlichen Diagrammen zurück. Der Kunde könnte auch von Prognosen profitieren. Zum Beispiel basierend auf der erwarteten Reichweite und dem geplanten Werbebudget würde das System Umsatzprognose machen.
Ergebnisse
Während der letzten Projektphase konnte das neue System mehrere Abfragen bis zu 100-mal schneller als die veraltete Lösung verarbeiten. Mit den wertvollen Erkenntnissen, die die Analyse von fast 30.000 Attributen brachte, war der Kunde in der Lage, die Muster der Mediennutzung weltweit zu verstehen und sich ein klares Bild von verschiedenen Märkten zu machen.
Technologien und Tools
Apache Hadoop, Apache Hive, Apache Spark, Python (ETL), Scala (Spark, ETL), SQL (ETL), Amazon Web Services (Cloud-Speicher), Microsoft Azure (Cloud-Speicher), .NET (Desktop-Anwendung).