4 Meilensteine für eine erfolgreiche Implementierung von Hadoop


Iryna ist Forscherin in Data Analytics bei ScienceSoft, einem IT-Beratungs- und Softwareentwicklungsunternehmen mit Hauptsitz in McKinney, Texas. Mit einem Fokus auf Business Intelligence, Big Data und Data Science untersucht Iryna Trends und Technologien in der Welt der Datenanalyse sowie wichtige Herausforderungen und Lösungen.
Wie viele Generationen haben versucht, die geheime Erfolgsformel zu finden! Obwohl wir in Unkenntnis über die universelle Formel sind, wissen wir auf jeden Fall, wie man bei der Implementierung von Hadoop Erfolg erzielen kann. In unserem Artikel gehen wir näher auf eine Mischung aus Business-Fragen und technischen Details ein, die die Grundlage für ein großartiges Hadoop-Implementierungsprojekt bilden. Beginnen wir jedoch damit, die klaren Grenzen von Hadoop zu identifizieren, weil der Begriff unterschiedliche Bedeutungen vermittelt. In diesem Artikel bedeutet Hadoop vier Grundmodule:
- Hadoop Distributed File System (HDFS, auf Deutsch: Verteiltes Dateisystem) - eine Speicherkomponente.
- Hadoop MapReduce - ein Framework für die Datenverarbeitung.
- Hadoop Common - eine Sammlung von Bibliotheken und Dienstprogrammen, die andere Hadoop-Module unterstützt.
- Hadoop YARN - ein Ressourcen-Manager.
Unsere Definition umfasst Apache Hive, Apache HBase, Apache Zookeeper, Apache Oozie und andere Elemente des Hadoop-Ökosystems nicht.
Meilenstein 1. Entscheiden Sie: eine On-Premises- oder Cloud-Lösung
Was als einfache Entweder-Oder-Wahl erscheint, ist in der Tat ein wichtiger Schritt. Und um diesen Schritt zu machen, sollte man damit beginnen, die Anforderungen aller Stakeholder zu sammeln. Ein klassisches Beispiel dafür, was passiert, wenn diese Regel vernachlässigt wird: Ihr IT-Team plant, die On-Premises-Lösung zu implementieren, und Ihr Finanzteam sagt, dass keine CAPEX-Geldmittel (Investitionsausgaben) zur Verfügung stehen, um das zu ermöglichen.
Die Liste der Faktoren, die berücksichtigt werden müssen, ist nahezu endlos. Um die Wahl zwischen On-Premises und in der Cloud zu treffen, sollte man jeden Faktor bewerten und sich basierend auf den Prioritäten für etwas entscheiden. Unsere Berater haben mehrere hochrangige Faktoren zusammengefasst, die vor einer Entscheidung abgewogen werden sollten.
Betrachten Sie Hadoop On-Premises als Option, wenn:
- Sie den Umfang Ihres Projekts klar verstehen und für ernsthafte Investitionen in Hardware, Büroräume, Entwicklung von einem Support-Team usw. bereit sind.
- Sie die volle Kontrolle über Hardware und Software haben möchten und glauben, dass die Sicherheit von größter Bedeutung ist.
Betrachten Sie Hadoop in der Cloud als Option, wenn:
- Sie sich nicht sicher sind, welche Speicherressourcen Sie in Zukunft benötigen werden.
- Sie nach Elastizität streben, zum Beispiel müssten Sie Spitzenbelastung bewältigen (ähnlich wie bei den Verkäufen am Black Friday („schwarzen Freitag“) im Vergleich zu Standardtagen).
- Sie kein hochprofessionelles Verwaltungsteam haben, um die Lösung zu konfigurieren und zu unterstützen.
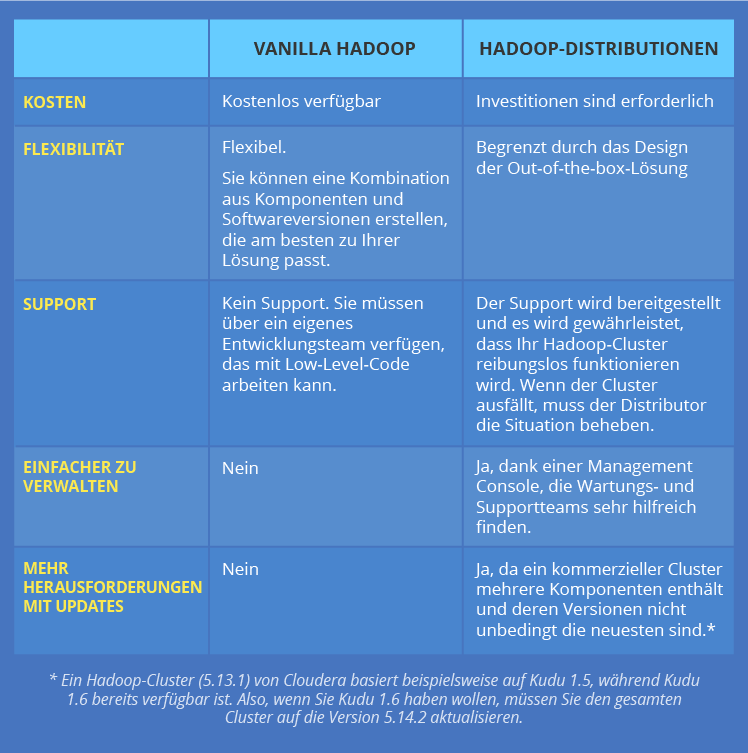
Meilenstein 2. Entscheiden Sie: Vanilla Hadoop oder Hadoop-Distributionen
Wenn Sie unter allen Technologien Hadoop wählen, bedeutet das nicht, dass der Auswahlprozess abgeschlossen ist. Sie müssen entweder für Vanilla Hadoop oder eine der Anbieter-Distributionen (z. B. von Hortonworks, Cloudera oder MapR geliefert) auswählen.
Lassen wir uns zuerst die Begriffe klären. Vanilla Hadoop ist ein Open-Source-Framework von Apache Software Foundation, während Hadoop-Distributionen kommerzielle Versionen von Hadoop sind, die mehrere Frameworks und von einem Anbieter hinzugefügte kundenspezifische Komponenten umfassen. Zum Beispiel umfasst Cloudera Hadoop-Cluster Apache Hadoop, Apache Flume, Apache HBase, Apache Hive, Apache Impala, Apache Kafka, Apache Spark, Apache Kudu, Cloudera Search und viele andere Komponenten.
Unsere Hadoop-Berater haben diese beiden Alternativen gegenübergestellt, um die wesentlichen Unterschiede hervorzuheben:
Meilenstein 3. Berechnen Sie die erforderliche Größe und Struktur von Hadoop-Clustern
Riesige und ständig wachsende Datenvolumen gehören zu einem der spezifischen Merkmale von Big Data. Natürlich müssen Sie Ihren Hadoop-Cluster so planen, dass ausreichend Speicherplatz für Ihr aktuelles und zukünftiges Big Data vorhanden ist. Wir werden diesen Artikel mit Formeln nicht überladen. Doch sind hier einige wichtige Faktoren bei der Berechnung der Clustergröße zu berücksichtigen:
- Datenmenge, die von Hadoop aufgenommen werden soll.
- Das erwartete Wachstum von Datenströmen.
- Replikationsfaktor (z. B. in einem HDFS-Cluster mit mehreren Knoten gibt es 3 Kopien in der Regel).
- Kompressionsrate (falls verwendet).
- Platz, der für die sofortigen Ergebnisse von Mappern reserviert wird (in der Regel 25-30% des gesamten verfügbaren Speicherplatzes).
- Speicherplatz, der für Betriebssystemaktivitäten reserviert werden soll.
Es kommt häufig vor, dass Unternehmen die Größe ihres Clusters basierend auf angenommenen Spitzenlasten definieren und am Ende mehr Cluster-Ressourcen haben, als es erforderlich ist. Wir empfehlen, die Clustergröße unter Berücksichtigung der Standardlasten zu berechnen. Sie sollten jedoch auch planen, wie Sie mit den Spitzen umgehen. Die Szenarien können unterschiedlich sein: Sie können sich für die Elastizität entscheiden, die die Cloud bietet, oder Sie können eine Hybrid-Lösung entwerfen.
Eine andere Sache, die berücksichtigt werden muss, ist die Verteilung der Arbeitsbelastung. Da verschiedene Jobs um dieselben Ressourcen konkurrieren, ist es notwendig, den Cluster so zu strukturieren, um die Belastung auszugleichen. Wenn Sie neue Knoten hinzufügen, stellen Sie sicher, dass ein Load Balancer in Gang gesetzt wird. Andernfalls können Sie vor einer Situation stehen, die in der folgenden Abbildung dargestellt ist: Neue Daten konzentrieren sich auf neu hinzugefügte Knoten, was zu einem verringerten Datendurchsatz im Cluster oder sogar zum vorübergehenden Ausfall des Systems führen kann.
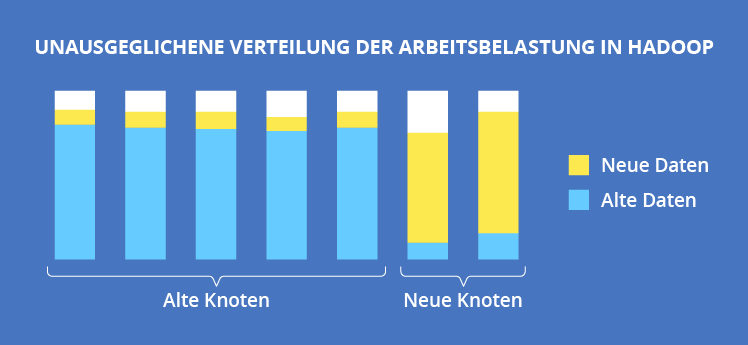
Datenquelle: Real-World Hadoop von Ted Dunning, Ellen Friedman
Meilenstein 4. Integrieren Sie alle Elemente der Architektur
Die Architektur Ihrer Lösung wird auf jeden Fall mehrere Elemente enthalten. Wir haben bereits klargestellt, dass Hadoop selbst aus mehreren Komponenten besteht. Bei der Lösung ihrer geschäftlichen Aufgaben können Unternehmen die Architektur mit weiteren zusätzlichen Frameworks bereichern. Zum Beispiel kann ein Unternehmen die Funktionalität von Hadoop MapReduce für unzureichend halten und seine Lösung mit Apache Spark verbessern. Oder ein anderes Unternehmen muss Streaming-Daten in Echtzeit analysieren und entscheidet sich für Apache Kafka als zusätzliche Komponente. Aber diese Beispiele sind ziemlich einfach. In Wirklichkeit müssen Unternehmen zwischen zahlreichen Kombinationen von Frameworks und Technologien wählen. Und all diese Elemente sollten natürlich reibungslos zusammenarbeiten, was in der Tat eine große Herausforderung darstellt.
Selbst wenn zwei Frameworks als höchst kompatibel erkannt werden (z. B. HDFS und Apache Spark), bedeutet das nicht, dass Ihre Big-Data-Lösung reibungslos funktionieren wird. Eine falsche Wahl der Versionen - und statt einer blitzschnellen Datenverarbeitung müssen Sie das System bewältigen, das überhaupt nicht funktioniert.
Und Apache Spark ist zumindest ein ganz anderes Produkt. Was werden Sie sagen, wenn die Probleme sogar von den inneren Elementen Ihres Hadoop-Ökosystems kommen? Niemand erwartet, dass Apache Hive, der für die Abfrage der in HDFS gespeicherten Daten ausgelegt wurde, sich nicht mit dem letzteren integrieren kann, aber manchmal ist es so.
Also, wie wird man erfolgreich?
Wir haben unsere Formel für eine erfolgreiche Hadoop-Implementierung geteilt. Bei ihren Komponenten handelt es sich um durchdachte Entscheidungen bei dem Einsatz in der Cloud oder On-Premises, bei der Auswahl von Vanilla Hadoop oder einer kommerziellen Version, bei der Berechnung der Clustergröße und der problemlosen Integration. Natürlich ist diese Formel vereinfacht, weil sie allgemeine Fragen behandelt, die jedem Unternehmen innewohnen. Jedes Geschäft ist jedoch einzigartig und zusätzlich zur Lösung von Standard-Herausforderungen sollte man bereit sein, eine Vielzahl von individuellen Aufgaben zu bewältigen.