Lösung zum Big Data Management für das IoT
Kunde
Der Kunde ist ein Unternehmen, das in den USA tätig ist. Aufgrund seiner umfangreichen Erfahrung in der Telekommunikation hat der Kunde beschlossen, einen neuen durch eine mobile Applikation verwalteten Service einzuführen, der es Tierhaltern ermöglicht, die Standorte ihrer Haustiere mithilfe tragbarer Tracker zu überwachen.
Herausforderung
Der Kunde wollte eine Lösung für das Big Data Management, die es den Benutzern ermöglichen würde, immer aktuell über die Standorte ihrer Tiere informiert zu sein, Echtzeit-Benachrichtigungen über kritische Ereignisse zu erhalten sowie auf die Berichte über die Anwesenheit ihres Haustiers zuzugreifen.
Die Lösung sollte die Übertragung von Medieninhalten (Audio, Video und Fotos) ermöglichen, sodass Tierbesitzer mit ihren Haustieren „sprechen könnten oder sehen würden, wo sich ihre Tiere zu einem bestimmten Zeitpunkt befinden.
Da der Kunde erwartete, dass die Anzahl der Benutzer ständig wachsen wird, sollte die Lösung gut skalierbar sein, um eine zunehmende Datenmenge zu speichern und zu verarbeiten
Lösung
Um sicherzustellen, dass die Lösung hoch skalierbar ist, haben die Big-Data-Berater von ScienceSoft sie in der Cloud bereitgestellt und Apache Kafka, Apache Spark und MongoDB als Basis genommen.
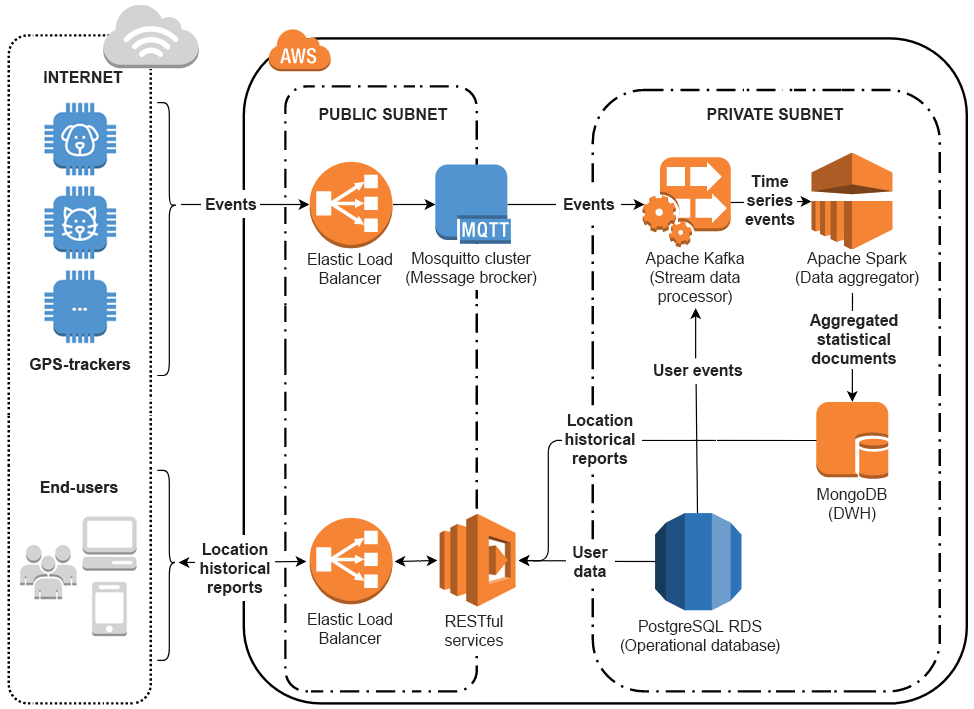
Wie die Lösung funktioniert:
- Mehrere GPS-Tracker übertragen Echtzeitdaten über den Standort des Tieres sowie über Ereignisse (z. B. schwache Batterie, Verlassen eines sicheren Territoriums usw.) an den Message Broker mittels MQTT-Protokolls. Das Protokoll wurde gewählt, um eine gerätefreundliche Schnittstelle zu gewährleisten und die Akkulaufzeit des Mobiltelefons zu verlängern.
- Ein Stream-Datenprozessor auf Basis von Apache Kafka überträgt Daten aus mehreren MQTT-Topics (Themen), verarbeitet sie in Echtzeit und überprüft die Datenqualität. Kafka Streams (eine Komponente von Apache Kafka) macht Push-Benachrichtigungen möglich und sorgt für einen sicheren Datentransfer.
- Ein in Apache Spark implementierter Daten Aggregator verarbeitet Daten im Speicher, aggregiert sie nach Stunden, Tagen, Wochen und Monaten und überträgt sie in ein Data Warehouse. Für Letzteres schlug das Team von ScienceSoft die MongoDB-Technologie vor, weil sie zahlreiche Ereignisse als einzelnes Dokument speichern kann (nach Stunden, Tagen, Wochen). Außerdem ermöglicht das dokumentenorientierte Design direkte Aktualisierungen, die zu einem großen Leistungsgewinn führen.
- Operative Datenbank in PostgreSQL RDS speichert Benutzerprofile, Konten und Konfigurationsdaten.
- RESTful-Services trennen die Benutzerschnittstelle vom Datenspeicher und stellen Zuverlässigkeit, Skalierbarkeit und Unabhängigkeit von einem Plattformtyp oder einer Programmiersprache sicher.
Ergebnisse
Der Kunde erhielt eine leicht skalierbare Lösung für das Big Data Management, mit der mehr als 30.000 Ereignisse pro Sekunde von 1 Millionen Geräten verarbeitet werden können. Dadurch können die Benutzer den Standort ihres Haustiers in Echtzeit verfolgen sowie Fotos, Videos und Sprachnachrichten senden und empfangen. Wenn ein kritisches Ereignis eintritt (z. B. wenn ein Haustier einen vom Haustierbesitzer eingestellten Geozaun überquert oder der tragbare Tracker des Haustieres "nicht in Kommunikation" steht), erhält der Benutzer Push-Benachrichtigungen. Tierbesitzer können auch auf stündliche, wöchentliche oder monatliche Berichte zugreifen, die automatisch festgelegt werden, oder manuell den Berichtszeitraum bei Bedarf abstimmen.
Technologien und Tools
Amazon Web Services, MQTT, Apache Kafka (Stream-Datenprozessor), Apache Spark (Daten-Aggregator), MongoDB (Data Warehouse), PostgreSQL RDS (operationale Datenbank), RESTful Web-Services.